近期在VoxSRC国际说话人识别比赛限定训练数据任务中(公开刷榜阶段),科大讯飞刷新世界纪录,等错误率(EER)降低到0.81%。同时,科大讯飞在学术界公开测试集合VoxCeleb1上取得0.63%的EER,是截止目前的State Of The Art(最好结果),上述两个新纪录表明科大讯飞说话人识别技术站在了世界前列。
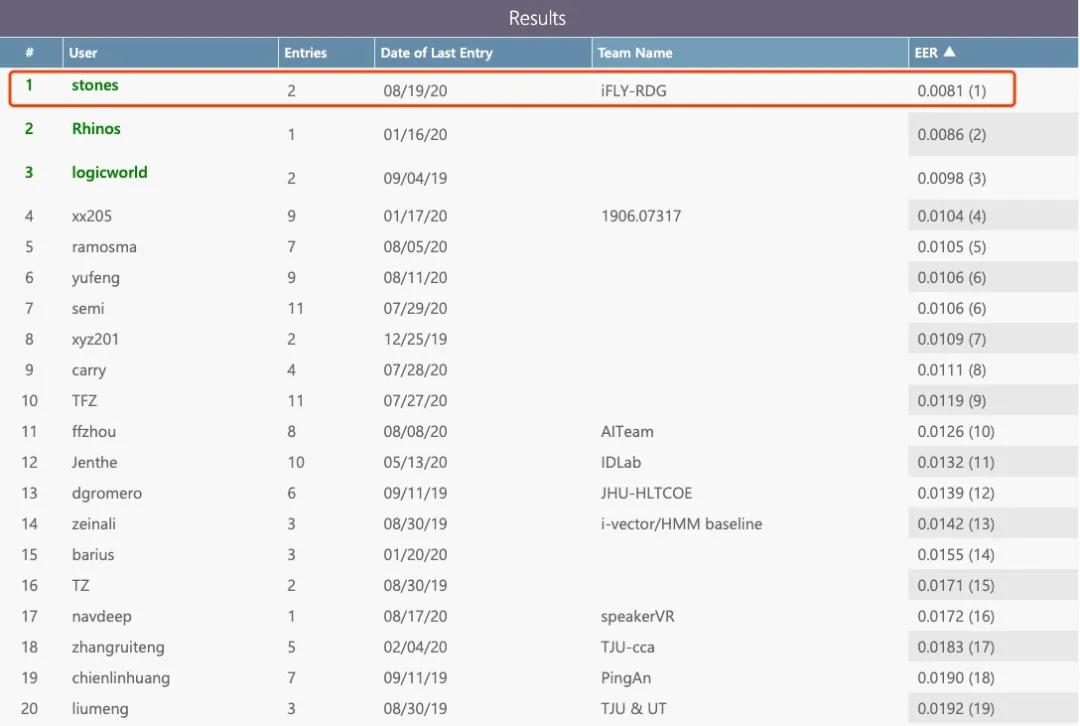
科大讯飞创造VoxSRC国际说话人识别比赛新纪录
(Task1: 限定训练数据)
VoxSRC国际说话人识别比赛
The VoxCeleb Speaker Recognition Challenge (VoxSRC)比赛是由英国牛津大学、韩国NAVER公司、美国斯坦福国际研究院语音技术与研究实验室和麻省理工学院林肯实验室组织发起的全球说话语音识别比赛,任务为文本无关(自由说)场景下的说话人确认任务,简单来说就是要机器判断两条语音是否来自同一个说话人。
VoxSRC比赛中的语音数据截取自海量互联网视频,覆盖多种录制设备、视频格式、语种、方言口音、室内室外场景等,需要参赛系统在限定训练数据的情况下解决跨信道、跨场景的说话人比对难题。
比赛极具挑战,参赛队伍高手云集,包括捷克布尔诺理工大学、美国约翰霍普金斯大学、比利时根特大学、微软雷德蒙德研究院等国际一流高校和知名研究机构,以及清华大学、昆山杜克大学、平安科技、依图科技等国内一流院校和企业。
科大讯飞说话人识别技术的特色
说话人识别是指利用人的声音来检测说话人身份的技术,是一项重要且具有挑战性的研究课题。与其它生物识别技术相比,说话人识别技术利用语音信号进行身份确认,具有成本低廉、采集简便、易于存储、难于模仿、交互友好等特点,同时也可以通过电话或网络等方式进行远程操作。因此,说话人识别技术在智能家居、智能办公等诸多领域都具有良好而广阔的应用前景。
早在2008年科大讯飞就取得了NIST国际权威说话人识别比赛的冠军,在深度学习应用到说话人识别领域之后,科大讯飞坚持技术创新并取得一系列突破。比如针对VoxSRC这种大规模、多场景、文本无关的说话人识别任务,采用变分编解码网络替代传统的PLDA,在训练过程中采用对抗样本的自动生成+训练解决模型过拟合问题,大幅提升了说话人识别的效果。
依托说话人识别技术的长期积累,科大讯飞还致力于说话人分离技术的研究,能力涵盖电话场景、会议场景的非实时说话人分离以及实时说话人分离。全场景、全能力的说话人分离技术结合科大讯飞语音识别软件,为用户打造更准确、更智能的办公体验。
科大讯飞说话人识别技术的应用
科大讯飞长期致力于智能语音技术的源头创新及产业化应用,并不断挑战说话人技术在实际应用中的技术难题,为多个产品赋能说话人识别语音转写能力。
智慧家庭产品中,以讯飞说话人识别为基础,结合每个家庭成员的个人喜好,给出差异性的搜索和推荐,提升服务质量。
说话人分离是转写场景中的刚需,能够体现“AI+办公”的智能与便捷。讯飞录音笔是科大讯飞“AI+办公”产品族中的明星产品,能够自动区分语音中的多个说话人,为用户的编辑整理工作带来了极大的便利性。
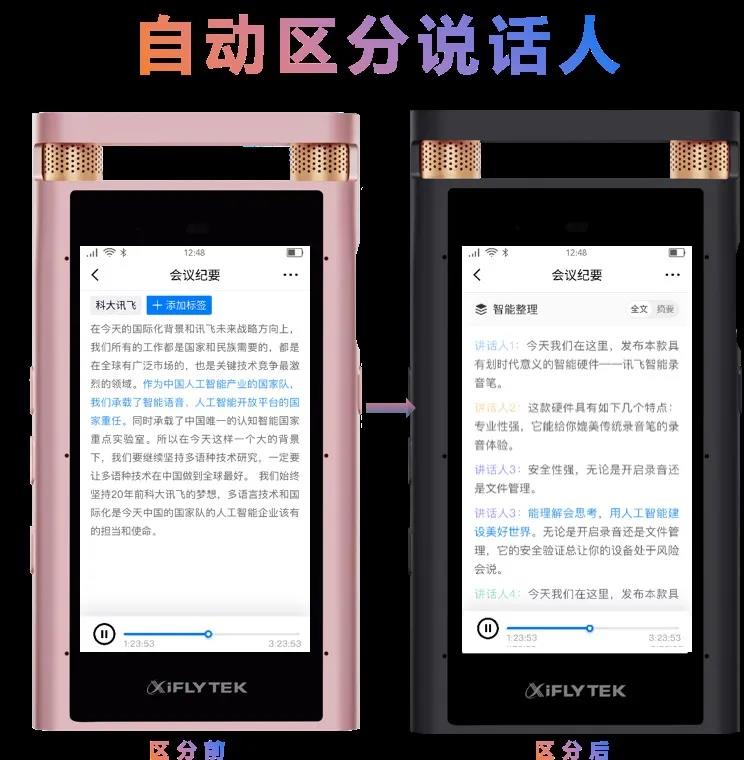
科大讯飞录音笔说话人分离功能示意图